OpenAI Whisper Transcription Testing

It feels like we're currently experiencing a renaissance in AI computing technology. The skills and hardware required to harness powerful AI software has dropped to the level that pretty much any moderately nerdy person can make use of it. While the past few months have mostly seen public advancements in image generation tech (which I used to generate the header image of this article,) OpenAI just released something very different: Whisper is a general purpose speech recognition model. It is trained on a large dataset of diverse audio and can perform multilingual speech recognition as well as speech translation and language identification.
While I've noticed that subtitles on various video streaming platforms have been slowly improving over the years, I've generally found it to be underwhelming. So I was intrigued to learn that I could now wield the power of AI on a highly trained data set with only a few commands. And I figured I could find a great set of audio data to stress test this software....
Transcribing Audio in 4 Steps
I ran the following commands (on Linux) to create the text output that I then analyzed for accuracy:
- sudo apt update && sudo apt install ffmpeg && sudo apt install yt-dlp && sudo apt install python3-pip
- pip install git+https://github.com/openai/whisper.git
- yt-dlp --extract-audio --audio-format mp3 <YouTube video URL>
- whisper ./<audio filename>.mp3 --model medium
You'll immediately see your CPU getting pegged with a ton of work and the Whisper software will spend a little bit detecting the language in the file if you haven't explicitly passed it as a parameter. Several minutes later, you should see the transcribed text start to be printed to the screen.
An Audio Stress Test
What audio data have I decided to use for my research? It's from a highly technical talk about Lightning Network by one of the fastest speakers I've ever heard, Olaoluwa Osuntokun.
Why this video?
- It includes highly technical jargon that may be challenging to transcribe.
- The average person speaks at 150 words per minute while in this clip Olaoluwa speaks at 280 - 300 words per minute; it's difficult for many humans to keep up.
- Brian Bishop transcribed this talk when it was given in 2018 and hosts the text here. I thought it might be a useful comparison.
I've created a github repository with all of the data (inputs and outputs) used for this article in case anyone wants to reproduce the results.
Transcription Performance
After pegging my laptop's Core i7 9750H 2.6GHz (6 core) CPU for half an hour, Whisper had only processed the first minute of the video. At this rate it was going to take 16 hours to finish, so I decided to kill the process after it transcribed 15 minutes of audio.
I also tried running the same tests on my Core i7 8700 3.2GHz (6 core) desktop machine to see if the hardware would make a substantial difference. Based upon the benchmarks, the 8700 ought to be somewhat faster.
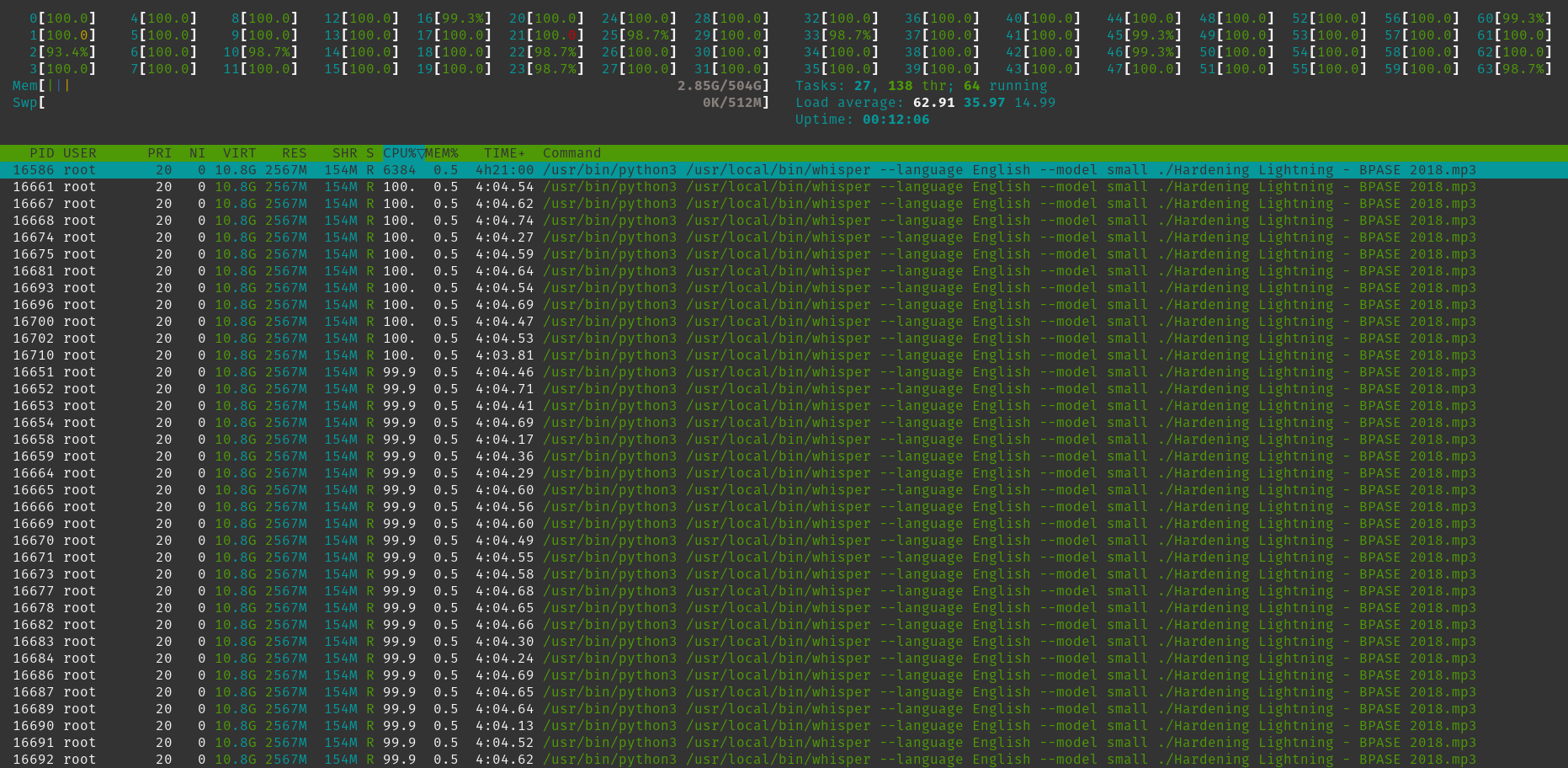
Next I tried a Linode instance with 64 virtual CPUs. I was hoping that if the software is highly parallelized then this should be close to 10 times faster. From looking at the machine's activity once I started running Whisper, it seemed to be firing on all cores...
Finally, I decided to test transcription using a GPU rather than a CPU. I spooled up a Linode instance with a RTX6000 GPU and followed these instructions to install the CUDA drivers. The results were impressive - it only takes seconds to transcribe a minute of audio, even for the large model! This is noteworthy because once you surpass the "realtime" barrier it means this transcription software is a candidate for being used to transcribe live events.
NOTE: I later tried to reproduce these tests on a Windows gaming PC I own and wasted hours trying to figure out why Whisper was unable to use my CUDA compatible GPU. I finally figured out that you have to install a different version of torch:
pip uninstall torch
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116
The following performance stats are based upon how long it took to process the first 10 minutes of the audio file.
So we can see that the desktop processor was marginally faster than my laptop processor. But the big disappointment was the 64 CPU virtual server. It offered basically the same performance as my 6 core desktop processor! It makes me wonder if the software is properly optimized to be able to make the best use of that many processors, or if a Linode "virtual CPU" just has exceptionally poor performance. It's hard to say without further testing, and my experience trying to get high CPU instance virtual servers up and running on different cloud computing platforms resulted in me running into more roadblocks than I expected.
Transcribing with the GPU was anywhere from 25X to 63X faster than with a CPU - and the relative speedup is actually higher on the higher quality models.
We can clearly see that transcribing with the default "small" model versus the higher quality "medium" model is at least 3 times faster. And the medium model is twice as fast as the large model! Naturally, we must ask the question of if the performance hit is worth the increased accuracy...
Transcription Accuracy
In an attempt to get a rough quantification of accuracy I decided to manually compare the first 15 minutes of 4 different transcripts:
- Whisper "small" (default) model
- Whisper "medium" model
- Whisper "large" model
- Brian Bishop's transcript
In order to measure the accuracy of each, I first needed a 100% accurate text. I manually transcribed the first 15 minutes myself; it can be found here.
I counted ~212 transcription errors with the default small model. Given that the small model output a transcript with 4502 words, that gives us an accuracy rate of around 95.3%. Not bad.
I only counted 29 transcription errors that were output by the medium model. Around a dozen were due to highly technical terms while a lot of the others were honestly quite difficult for even me to determine what the word was after listening to it several times, and I had to use context clues from the rest of the sentence. Given that the medium model output a transcript with 4413 words, that means an accuracy rate of an astounding 99.3%!
Unfortunately I found at least 66 transcription errors in the large model's output. It's still a 98.5% accuracy rate, but certainly not worth the halving in processing performance.
When I tried to compare Brian Bishop's transcript to my reference, I realized that there wasn't much point - Brian is not striving for word-for-word precision. He's transcribing in realtime (unlike Whisper) and looks for shorthand ways to summarize some phrases. There's no use comparing apples to oranges.
Miscellaneous Notes
I'm quite impressed that Whisper successfully transcribed "opcode" though I see that homonyms can be tricky - for example it output "state cash" rather than "state cache."
One nice thing is that Whisper manages to ignore irrelevant filler sounds like "ahhhh" and "ummmm." It also does a good job removing stammering and repeating of words that would otherwise make the transcript less legible. It seems like the higher the model quality, the better it is at filtering out this noise.
While Whisper didn't correctly transcribe "SHAChain" (it interpreted it as "shorchain") I'm incredibly impressed that it transcribed OpCheckSigFromStack accurately! Well, with the medium model. The default model transcribed "OP check SIG from stack."
Final Thoughts
You get a lot of bang for your buck just running the medium model on a desktop computer - that's what I'd recommend for most folks who are tinkering with this project.
If you have an nVidia graphics card available, it's a no-brainer to use it instead of a CPU because it's at least 25 times faster. You just need to ensure you have the CUDA drivers installed and pass "--device cuda" when running Whisper.
I certainly see a lot of potential for Whisper and similar transcription software. I didn't even try to test out the built-in translation functionality. But if it's also in the realm of 99% accuracy, then this is an insanely powerful tool that I expect will see a great deal of adoption in the coming years.




