Effects of DBcache Size on Bitcoin Node Sync Speed

I recently had someone point out on my Bitcoin Core Config Generator project that there are tradeoffs with high dbcache settings and initial block download performance on low powered devices.
What is dbcache? It's not exactly a cache in the traditional sense - it's mostly a write buffer and it prevents you from needing to regularly write the current state of the UTXO set to disk. This can be a performance improvement when syncing many blocks because you're avoiding having to make a ton of disk operations that are relatively slow.
What's the problem? In short, if your node crashes before the initial full sync is completed but you have a high enough cache setting that you never completely filled it, the node never flushes the UTXO set to disk. This means if you restart an interrupted sync it requires an incredibly resource intensive process of reindexing the blockchain in order to rebuild the UTXO set that you failed to persist to disk.
 jlopp
jloppThe discussion around these tradeoffs led to an interesting claim:
With a modern SSD there is very little reason to change the default especially because OS will use free RAM to opportunistically cache the filesystem in the free RAM anyway so a machine with higher RAM will always get an implicit speedup.
This claim made sense to me at a high level but I wasn't completely sure if it would hold true.
Testing Time
Naturally, I set forth to determine whether or not the theory could be proven with real world data. So I ran several node sync tests on my benchmark machine I've been using for 6 years. The raw results can be found in this spreadsheet.
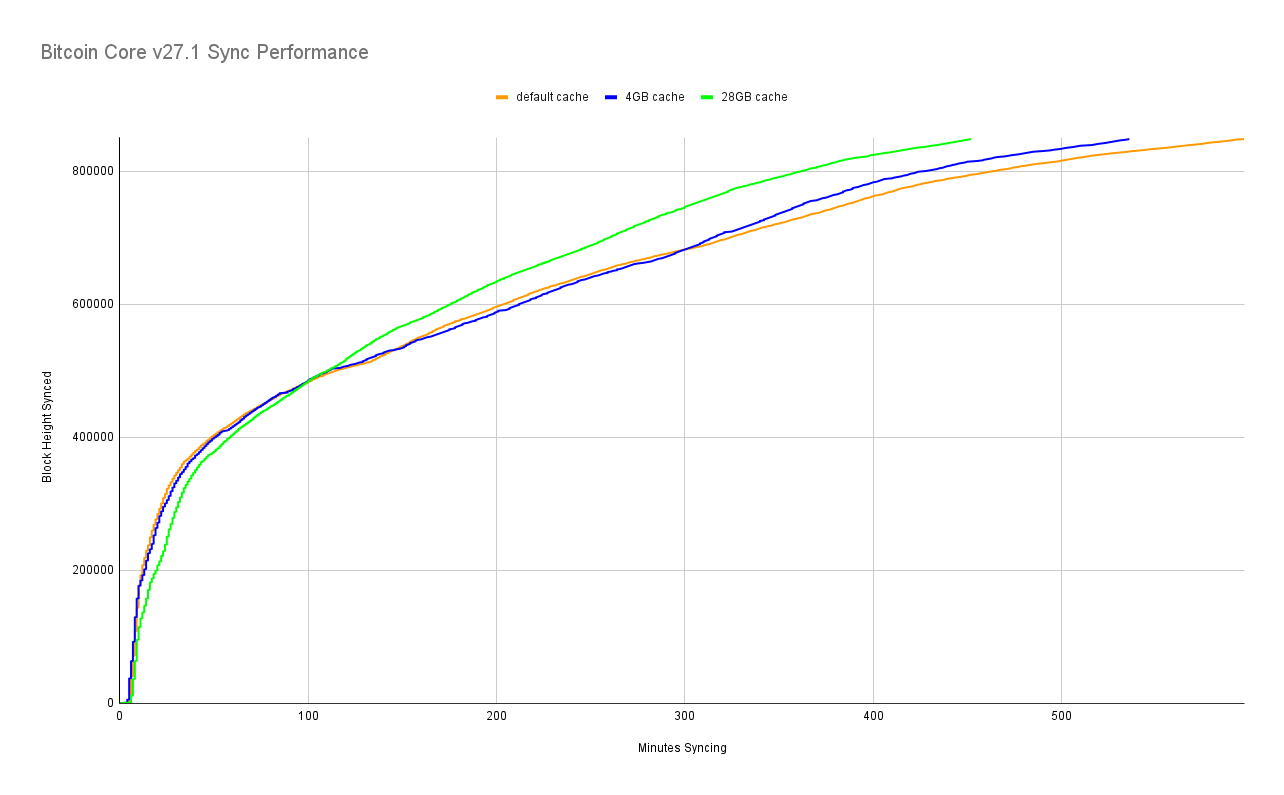
If you're wondering why it takes the node ~5 minutes to start syncing, that's because it's doing the synchronization of the block headers first before starting to download any blocks.
We can see here that the huge dbcache sync was 24% faster than the default cache sync: 452 minutes versus 597 minutes with default cache size. Whereas with a moderate 4 GB dbcache it's only 10% faster than the default, taking 536 minutes.
If you look closely at the chart you might notice that the slope / rate of syncing slows down a bit around block 820,000. As we can see from the code here, the "assumed valid block" for the Bitcoin Core v27.1 release was at height 824,000. So at that point the node starts having to perform more CPU intensive operations by verifying all of the signatures on transaction inputs. However, disk I/O still remains a larger factor (bottleneck) when it comes to sync performance.
Let's visualize the sync times slightly differently so that we can more easily compare the performance gap. This chart shows the delta between how many minutes it took my benchmark machine to reach a given block height with a 28 GB dbcache size versus with the default dbcache size of 450 MB.
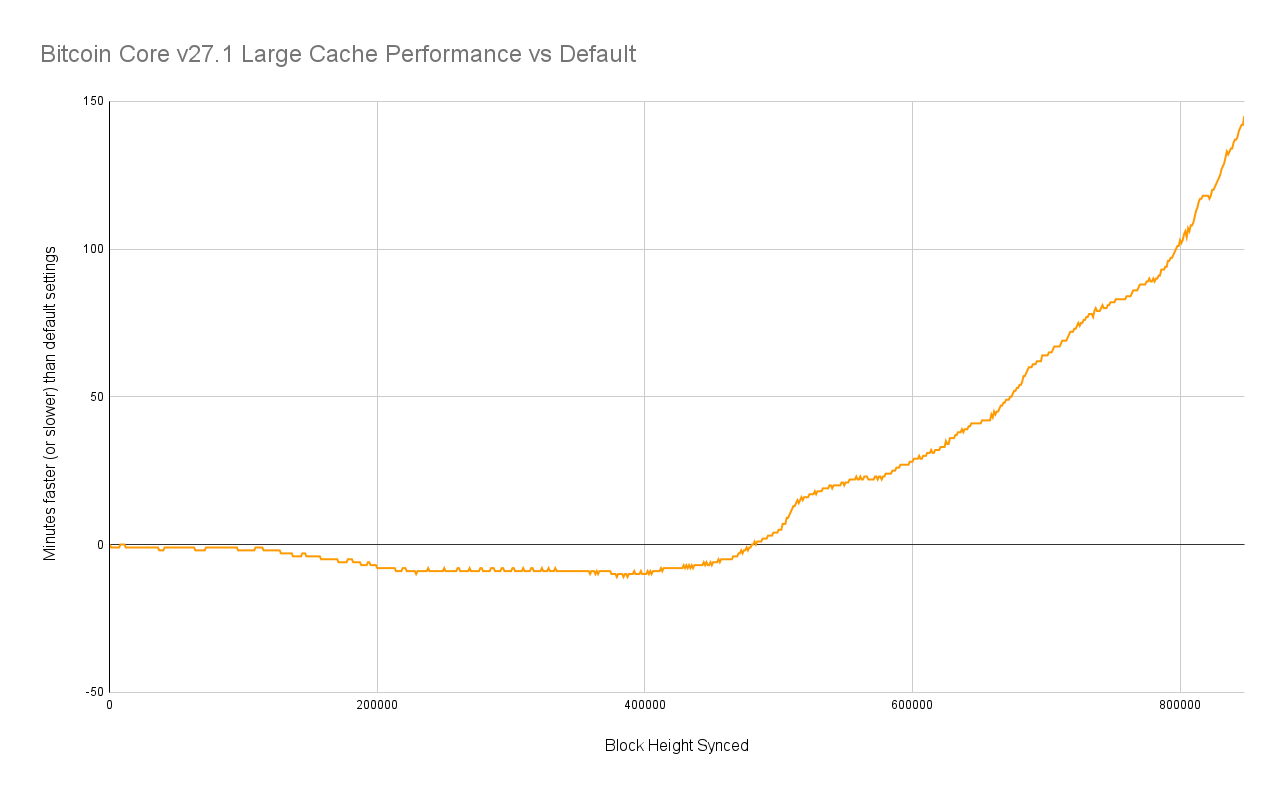
We can see they're pretty much neck and neck until block ~485,000 which takes my machine 100 minutes to reach. After that point, the large dbcache performance breaks away and never looks back. If I were to speculate as to why, my bet is that the default 450MB dbcache doesn't fill up until you hit that part of the blockchain, so after that point the default sync will start flushing the chainstate to disk regularly, thus slowing down the sync.
Conclusion
The theory doesn't appear to hold true, and I think the reason for that is because dbcache is not primarily used as a (read) cache. As such, node sync performance can not benefit from opportunistic filesystem caching at the operating system level.
However, the problem with interrupted initial node syncs is quite real. If you're performing a sync on low end hardware like a Raspberry Pi, it's probably worth the slightly slower sync time in order to protect against having to reindex the whole blockchain if the sync gets interrupted.




