2021 Altcoin Node Sync Tests
As I’ve noted many times in the past, running a fully validating node gives you the strongest security model and privacy model that is available to Bitcoin users; the same holds true for altcoins. As such, an important question for any peer to peer network is the performance and thus cost of running your own node. Worse performance requires higher hardware costs, which prices more users out of being able to attain the sovereign security model enabled by running your own node.
The computer I use as a baseline is high-end but uses off-the-shelf hardware. I bought this PC at the beginning of 2018. It cost about $2,000 at the time.
Note that very few node implementations strictly fully validate the entire blockchain history by default. As a performance improvement, most of them don’t validate signatures or other state changes before a certain point in time - some validate the past year or two while others only validate the past half hour. This is done as a trick to speed up the initial blockchain sync, but can make it harder to measure the actual performance of the node syncing since it's effectively skipping an arbitrary amount of computations. As such, for each test I configure the node so that it is forced to validate the entire history of the blockchain. Here are the results!
Ethereum Clients
According to the documentation on Ethereum.org there are half a dozen clients that support full validation. Let's see how they do!
We can see that the total amount of Ethereum data has increased significantly over the past year. Given that it requires 8 TB of disk space to run an archive node that keeps every historical state, that's out of the question for my machine with 1 TB of space.
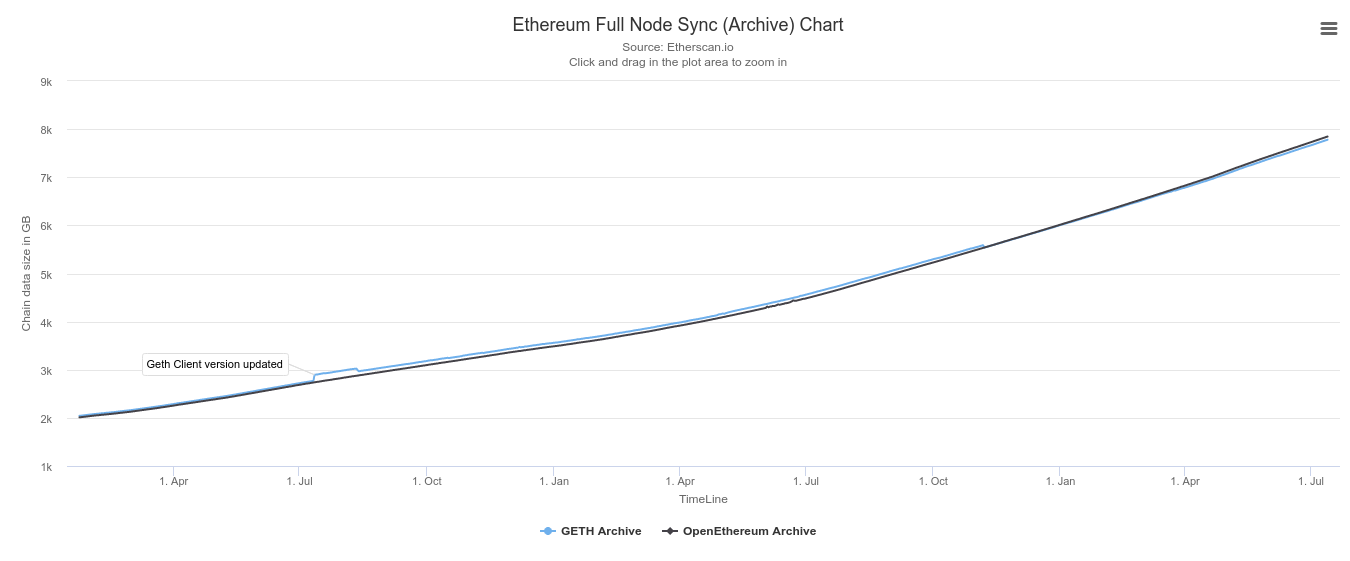
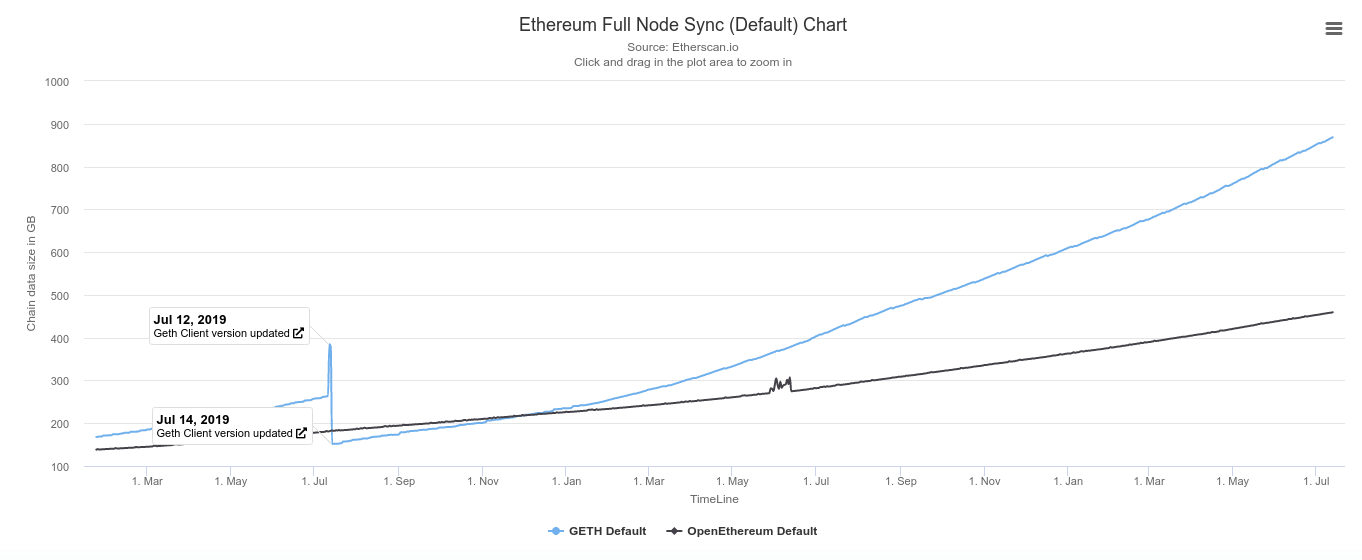
What's more concerning is that even a pruned geth node that only keeps recent state is approaching 1 TB of disk space... it looks like my machine won't be able to sync a pruned geth node after this year.
Besu
Besu's docs note that full sync requires 3 TB of disk space, which is problematic given that my machine has 1 TB. I decided to give it a shot anyway. I followed the directions here to install it.
I ran besu v21.171 with the arguments: --sync-mode FULL --pruning-enabled
It reached block 4700000 after 3 days and then slowed down considerably... until it finally crashed.
Full validation sync of Besu v21.171 (Ethereum) node reached block 5,006,800 in 4 days 15 hours before crashing due to running out of disk space on my benchmark machine.
— Jameson Lopp (@lopp) July 3, 2021
My rough extrapolation at a sync rate of 2 blocks per second would put it at ~50 days to reach chain tip.
At the time of the crash, Besu had:
- Read 9 TB from disk
- Wrote 16 TB to disk
- Downloaded 51 GB
- Used 10 GB of RAM
Like most ETH nodes, syncing appears to be bottlenecked by disk I/O.
Someone told me that I needed to run Besu as --fast-sync so that it would prune data. However, from reading the documentation this would not perform a full validation of the blockchain data - it only checks that the chain of block headers is unbroken.
Fast synchronization downloads the block headers and transaction receipts, and verifies the chain of block headers from the genesis block.
Geth
I ran Geth v1.10.4 with the following parameters in the config file:
[Eth] NetworkId = 1 SyncMode = "full" NoPruning = false DatabaseCache = 26000
Similar to Besu, it crashed when it ran out of disk space (I had ~750GB free)
Full validation (pruned) sync of Geth v1.10.4 got to height 11,415,000 after 5 days 21 hours on my benchmark machine and crashed due to running out of disk space. Rough extrapolation at 4 blocks per second would put it at 10 days, 2 hours to sync to chain tip height 12,869,000.
— Jameson Lopp (@lopp) July 21, 2021
At the time of the crash, geth had:
- Read 15.4 TB from disk
- Wrote 12.7 TB to disk
Bottlenecked on disk I/O, of course.
Erigon
Over the past year I've heard a lot about Erigon being the new kid on the blockchain, so my expectations were high. Erigon takes a completely new multi-stage approach to syncing the Ethereum blockchain.
Erigon recommends a 2 TB drive so I expect the default sync won't complete on a 1 TB. Thankfully one of the Erigon devs gave me a hint on how to reduce the required disk space.
I ran Erigon 2021.07.01-alpha with the argument: --storage-mode=
Full validation (with max pruning) sync of Erigon 2021.07.02-alpha to Ethereum block 12,770,000 on my benchmark machine took 2 days, 16 hours, 15 minutes.
— Jameson Lopp (@lopp) July 6, 2021
Erigon's multi-stage sync seems to have reduced total disk I/O by an order of magnitude, which is ETH's biggest bottleneck.
Erigon's p2p networking logic is well optimized; I saw spikes up to 100 MB/s.
Once it got to stage 6 (senders) it was using 95% of all my CPU cores and 9 GB RAM.
By the time Erigon finished syncing, it was using:
- 9 GB RAM
- Downloaded 310 GB
- Wrote 1.8 TB to disk
- Read 1.9 TB from disk
Given that Ethereum nodes tend to be bottlenecked to disk I/O, the fact that Erigon performs an order of magnitude fewer disk operations makes it clear why it's so much faster. However, it sounds like at least some of the performance gains are due to tweaking the validation logic.
It does not verify state root of every block, only does it at the end. And it does not match, it rolls back until it finds the place it matches. It is not all where the savings come from though. Also lots of indices are much more efficient to construction in one big batch
— Alexey Sharp 🦦🧬 (@realLedgerwatch) July 6, 2021
Alexey estimates that if Erigon validated the root state of every block, it would add another 9 days to the sync time. Should this disqualify Erigon as a fully validating node? It becomes more of a philosophical question, as it seems to me that validating every transaction from every block is "full validation" while performing extra validation for the state of the entire blockchain at each block is adding another level of assurance but it's basically like double checking your work. Since it checks the state root of the chain tip, if that matches what is expected then it's certain that the state roots of all the previous blocks will match expectations.
Nethermind
This was also my first time running Nethermind. Nethermind's docs list 9 different sync modes but funnily enough, none of them were what I wanted. After digging around the source files I found a config for "archive pruned sync" that I believe will do full validation but won't blow out the total disk storage required. Thus I ended up running it via:
./Nethermind.Runner -c configs/mainnet_archive_pruned.cfg
Full validation (pruned) sync of Nethermind v1.10.74 node to ETH block 12,810,000 on my benchmark machine ran out of disk space after 5 days 6 hours at block 6,178,044. Extrapolating from a run rate of 4 blocks / second suggests it would need another 19 days to sync to chain tip.
— Jameson Lopp (@lopp) July 12, 2021
At the time of crash, Nethermind was using:
- 17 GB RAM
- 370 GB downloaded
- 14.5 TB read from disk
- 15.3 TB written to disk
Like other Ethereum nodes, it's bottlenecked on disk I/O.
OpenEthereum (formerly Parity)
Synced OpenEthereum v3.3.0-rc4 with the following config values:
[network]
warp = false
[footprint]
pruning = "fast"
cache_size = 26000
scale_verifiers = true
Full validation sync of @OpenEthereumOrg v3.3.0-rc4 to block 13,150,000 on my benchmark machine took 33 days 2 hours 5 min.
— Jameson Lopp (@lopp) September 3, 2021
~5% CPU used
25 GB RAM used
484 GB downloaded
128 TB written to disk
162 TB read from disk
Unsurprisingly, the bottleneck was disk I/O as I saw it constantly reading / writing over 80 MB/S.
Trinity
It's worth noting that Trinity's web site states that it is alpha software that is not suitable for running in production environments.
The first time I started Trinty I let it run for an hour but never started syncing. Then I tried syncing testnet and had no problems. Eventually I realized it was an issue with not connecting to any bootstrap nodes, so I manually fed a peer "preferred" node to it on startup.
Unfortunately it crashed 10 minutes later.
Full validation sync of Ethereum Trinity 0.1.0a37 node got to block 51,000 on my benchmark machine in 10 minutes and then crashed with a deserialization error.
— Jameson Lopp (@lopp) June 28, 2021
So I filed a bug report:
 ethereum
ethereumAs a result of my tweet above, Trinity has been removed from the list of clients on the Ethereum.org documentation and the github repo was updated to reflect that it's not a maintained project and should not be used in production.
Ethereum in Summary
Ethereum's blockchain continues to grow and node implementations are struggling not to slow down significationly. Erigon seems to have found a way to massively improve performance by rethinking how nodes sync. However, my benchmark machine will no longer be able to perform full node syncs of Ethereum a year from now. Looking further ahead, it seems that the rollout of Ethereum 2.0 will deprecate the concept of fully validating the entire blockchain given that it will be spread out across many different shards.
Binance Chain
I followed the directions here to install and configure the node. I set the following config options:
fast_sync=true state_sync_reactor=false hot_sync=false hot_sync_reactor=false indexer = "null"
Full validation sync of Binance Chain 0.8.2 to block 8,520,000 on my benchmark machine took 13 days, 1 hour, 15 min.
— Jameson Lopp (@lopp) June 22, 2021
RAM: 5.4 GB
Total disk reads: 700 MB
Total disk writes: 515 GB
Machine was basically asleep; I estimate it could sync 20X faster if networking logic is improved.
I found it odd that the node was consistently downloading 300 KB/s and writing to disk. The CPU was practically asleep at only 5% usage. My best guess is that the networking logic has a lot of room for improvement in order to download data faster; the machine is clearly capable of processing data at 20X this rate.
Upon completion the node was using:
- 5.4 GB of RAM
- Total disk reads: 700 MB
- Total disk writes: 515 GB
- 34 GB stored in data directory
- 7 GB of logs stored
Not pruning all of that log data also struck me as a bit odd.
Cardano
This is my first attempt at running Cardano and I'm not 100% sure this is a full validation sync. Though given that only 17 GB of data was downloaded and 11 GB was stored, 11 hours is a long sync time if it skipped most of that validation.
I downloaded the linux executable from this link on Cardano's github README. But every time I ran the binary I got an odd error: "Error in $: key "AlonzoGenesisFile" not found. After a bit of searching around the forums it looks like something was wrong with the binary and it should not have been requiring that config yet - looks like it was a buggy nightly build rather than a release build. So I then downloaded the binary from the "hydra" link on the releases section.
Once I had the node up and running, figuring how the syncing process was going was annoyingly difficult. The node did not output percentage synced or even block height synced in the logs. I ended up having to query it via "cardano-cli tip" to periodically check the progress.
Cardano 1.27.0 node synced to height 5,823,000 in 9 hours 28 min on my benchmark machine. Used a max of 4.5 GB RAM and read no data from disk, suggesting good cache use. 24 GB was written to disk. Bottleneck appears to be software; hardware wasn't maxed out.
— Jameson Lopp (@lopp) June 8, 2021
At time of sync completion the node was using:
- 4.5 GB RAM
- 0 disk reads (nice)
- 24.1 GB disk writes
It's not quite clear where the bottleneck lies as neither my bandwidth, CPU, or disk I/O was maxed out.
Dogecoin
Dogecoin was practically dead / abandoned for 4 years until Elon Musk started bringing attention to it in 2020. From a development standpoint, improvements stalled in 2017. From a network standpoint, I heard many reports that it was very difficult to even sync a new node from scratch, presumably because it was hard to find peer nodes.
A small maintenance release, v1.14.3, was released in February 2021 to address network syncing issues.
I ran dogecoind with the same configuration I used for bitcoind:
assumevalid=0 dbcache=24000
Full validation sync of Dogecoin 1.14.3 to block 3,760,660 on my benchmark machine took 5 hours 34 minutes. It maxed out at 5 GB RAM, read 595 GB from disk & wrote 52 GB to disk. In GB/hour terms, sync speed is ~1/6th that of Bitcoin Core 0.21.
— Jameson Lopp (@lopp) June 9, 2021
At time of sync completion, dogecoind was using:
- 5 GB RAM
- 595 GB read from disk
- 52 GB written to disk
I noted during early syncing that a single CPU core seemed to be doing all of the work; it was not being parallelized. Also, the blocks appears to be getting processed in bursts which makes me suspect that it's not downloading them from multiple peers. It's interesting to see that Dogecoin takes about the same amount of time as Bitcoin Core despite having 1/7th as much data to sync. This goes to show how many performance optimizations Bitcoin Core has continued adding in recent years.
The surprising thing is how much data dogecoind read from disk - the only reason I can think of is that it's not using its UTXO cache properly.
EOS
In another first, I finally got around to trying to run EOS 2.1.0 - I had looked into it last year but it seemed like a pain.
EOS has no prebuilt debian binaries; it's not a supported OS. Thus I ended up having to run the build script and it failed; had to delete a line from the script that threw the error. When I ran it again, it exited with:
"On Linux the EOSIO build script only support Amazon, Centos, and Ubuntu."
So I deleted that silly OS check and ran it yet again, finally with some success.
After reading some documentation I set the following configs:
hard-replay-blockchain validation-mode:full checkpoints:null
And I ran the node via:
nodeos --plugin eosio::chain_plugin --force-all-checks
But nothing started syncing; after reading some more documentation I realized I needed to manually set peers. So I found a seed list with 20 peers, added them to the config.ini and started the node again. Unfortunately none of the peers accepted my connection attempts. Then I found a list of 50 node addresses in this config.ini on github and tried it, but once again to no avail.
After further digging through my node logs I saw that some of the peers had closed my connection with the following error: "go_away_message, reason = wrong chain"
So next I configured my genesis.json file per this guide and ran the node via:
nodeos --plugin eosio::chain_plugin --force-all-checks --delete-all-blocks --genesis-json ~/genesis.json
On this run the node crashed after 90 minutes at height 3654300 even though the state DB was less than 1 GB. It looks like the default max size for the chain state DB is 1 GB.
Database has reached an unsafe level of usage, shutting down to avoid corrupting the database. Please increase the value set for "chain-state-db-size-mb" and restart the process!
process_signed_block - 4b3b6f0 unlinkable_block_exception #3654354 7e9057faf99ab3ce...: Unlinkable block (3030001)unlinkable block 0037c2d27e9057faf99ab3cef429eb667077d33d943b378c8b5de1162527345b
So I wiped the node data, set the chain state max db size to 100GB, and started over.
After 24 hours it had synced 19M blocks, about 10% of the total blockchain.
After 4 days it had synced 42M blocks. If the next 150M blocks took 3 days for each 20M then I expect it would take at least 26 days to completely sync.
Conservative extrapolation (based upon 20% sync) for completion of EOS 2.1.0 full validation sync on my benchmark machine is 26 days. It could be a lot faster if the code was optimized to make better use of networking & CPU.
— Jameson Lopp (@lopp) June 28, 2021
By the time I gave up, the node had:
- Downloaded 200 GB
- Read over 5 GB
- Wrote over 5 TB
Syncing an EOS node felt very similar to syncing the Binance Chain node - my machine was not working hard. It seems like the bottleneck on this node's software is also at the networking layer, as it simply does not download enough blockchain data to hit any performance bottlenecks on my machine. The node syncing process stayed at a steady 100 KB/s - 200 KB/s data download pace, though sometimes it would drop to 0 for a bit as it tried to get data from unresponsive peers. Throughout this time the node was only using ~5% of my CPU power, leading me to estimate that syncing could potentially be 20X faster if only it could feed data into my machine faster. However , I did note that after block 6,000,000 the download speed sometimes spiked to nearly 10X faster around 2 MB/s. I never saw more than one CPU core working hard, so it seems validation is not parallelized.
Internet Computer
I wasn't originally planning on testing this but some tweets touting it as the fastest blockchain came up in my feed. My testing did not get very far before hitting a roadblock.
BAHAHAHAHAhttps://t.co/9qHu8REihq pic.twitter.com/RaNTWQCboz
— Jameson Lopp (@lopp) June 14, 2021
It's worth noting that it sounds like if you do have an Internet Computer node up and running, it updates its software automatically. This is a red flag to me - I'd be concerned about the "governance" model of this system. Suffice to say that ICP does not appear to be a permissionless system.
Litecoin
Running Litecoin is as straightfoward as running Bitcoin Core. Per usual, my litecoin.conf:
assumevalid=0 dbcache=24000
Full validation sync of Litecoin Core v0.18.1 to block 2,074,000 on my benchmark machine took 3 hours 10 min.
— Jameson Lopp (@lopp) June 22, 2021
RAM: 5.0 GB
Total disk reads: 4 MB
Total disk writes: 47 GB
At time of sync completion, Litecoin was using:
- Total disk reads: 4 MB
- Total disk writes: 47GB
- RAM: 4.6 GB
Note that Litecoin syncs roughly the same amount of data as Dogecoin and yet is almost twice as fast - they are doing a better job keeping up with Bitcoin Core's performance updates. We can also see that it read practically no data from disk, suggesting that it was able to keep the entire UTXO set cached at all times, unlike Dogecoin.
Monero
My monero config:
max-concurrency=12 fast-block-sync=0 prep-blocks-threads=12
Full validation sync of monero 0.17.2.2 to block 2375800 on my benchmark machine took 1 day 21 hours 7 minutes. Caching seems less effective now; 141GB were read from disk while 510GB were written. Biggest bottleneck still seems to be software; no hardware gets maxed out.
— Jameson Lopp (@lopp) June 6, 2021
At time of sync completion the node used:
- 2 GB RAM (seems perhaps it could probably benefit from using more?)
- Disk Reads: 141 GB
- Disk Writes: 510 GB
Bottleneck was certainly the CPU; in later blocks I noticed that a single core would be pegged while the others were idle.
One aberration I noted was that the node was regularly receiving a variety of different "top block candidates" and seemed to be syncing 4+ different blockchain forks simultaneously which I can am sure slowed down syncing significantly. From the logs it appeared that these stale peers would eventually get blocked and my node would stop syncing data from them, but it's not clear why it bothered to sync data from a fork with a chaintip that was several years old in the first place.
Syncing was significantly (+20 hours) longer than last year, presumably because there is far more data - another 200GB to download, verify, and store.
Polkadot
I've never run Polkadot before; as far as I can tell the default is full validation. At least, I didn't find any options that force a mode of extra validation. I ran the node with a single non-default config:
polkadot --db-cache 24000
Sync of Polkadot v0.9.3 to block 5,420,000 on my benchmark machine took 4 hours 50 minutes.
— Jameson Lopp (@lopp) June 14, 2021
4 GB of data downloaded
12.8 GB RAM max used
7.5 GB read from disk
337 GB written to disk
29 GB of disk storage used once complete; turns out 25 GB of that was just log files...
Oddly enough, the node just simply didn't seem to be doing much work. Most of the time all 12 CPU cores were quiet, with 1 core doing a few seconds of work every 10 seconds or so. Bandwidth usage was also low, with a 1 MB/s spike every 10 seconds or so. So it seems like the node is not queuing up a ton of data, and when it does receive data to validate, it's not parallelized. It seems that there are likely plenty of software optimizations to be made so that the node can make better use of the hardware upon which it's running.
Similar to Binance Chain, it generates an obscene amount of log files that really ought to get pruned.
Ripple
I used to run ripple nodes when I managed infrastructure for BitGo, though I've never tried doing so on a personal machine. I recall that the requirements were pretty high several years ago and our nodes would often lag behind the latest ledger entries. From looking at their recommended specs, it looks like you should be able to make do with 32GB of RAM, though unless you have 20TB of disk space you'll want to enable history deletion, which is analogous to pruning.
I synced rippled which only verifies the most recent 512 ledgers which is really only about the most recent half hour of activity. It only took 5 minutes to complete; the node downloaded 1.4 GB of data.
I haven't been able to find a configuration that would allow me to sync every ledger (block) from genesis while pruning data along the way. This is because of how ripple's "pruning" configs work.
[ledger_history] lets you set the number of past ledgers to acquire on node startup and the minimum to maintain while running. Nodes that want complete history can set this to "full."
[online_delete] has a minimum value of 256 (about 15 minutes) and enables automatic purging of ledger records older than the value set. Must be greater than or equal to ledger_history.
I tried running rippled with ledger_history = "full" and online_delete = 10000 and the node didn't complain, but neither did it appear to sync from genesis - it only synced the most recent 10000 ledgers. My rough guess is that it would take weeks if not months to sync from genesis if you had the hardware to do so.
Solana
Solana is a relatively new network that is a top 10 asset at time of writing. I looked into running a node and checked out the hardware requirements in their technical documentation. I did a double take when I saw that the bare minimum RAM is 128GB while 256GB is recommended. Recall that my benchmark machine has 32GB of RAM...
"Solana can process 50,000 transactions per second!"
— Jameson Lopp (@lopp) June 7, 2021
OK, and what's the cost of running a full node?
*spits out coffee* pic.twitter.com/RFK43Mc2Lt
I had an exchange operator reach out to me after I made this tweet, saying that it's not feasible to sync a Solana node and fully validate all the data created since genesis, because 300KB of new data arrives every half a second.
Unlike every other node I've run, it's not as simple as just downloading and executing the binaries. I next had to follow the instructions here.
$ sudo solana-sys-tuner --user jameson $ solana-validatorerror: The --identityargument is required $ solana-keygen newGenerating a new keypair Wrote new keypair to /home/jameson/.config/solana/id.json $ solana-validator --identity ~/.config/solana/id.json Failed to open ledger genesis_config "No such file or directory"
After digging through several pages of documentation I found this page began to understand that the genesis config gets downloaded from the trusted cluster, so then I ran
$ solana config set --url https://api.mainnet-beta.solana.com $ solana config set --keypair /home/jameson/.config/solana/id.json
I chuckled when I read this in the docs:
All four --trusted-validators are operated by SolanaI next tried to run the node via:
$ solana-validator --limit-ledger-size --identity ~/.config/solana/id.json --entrypoint entrypoint.mainnet-beta.solana.com:8001
I finally made a bit more progress but next the node crashed with network errors
Checking that tcp ports 8899, 8900, 8000 are reachable from 34.83.231.102:8001
ERROR Received no response at tcp/8899, check your port configuration
ERROR Received no response at tcp/8900, check your port configuration
ERROR Received no response at tcp/8000, check your port configuration
Interestingly, the above IP address is owned by Google; I wonder if this means that Solana is running their validators in Google Cloud...
It took me a moment to figure out that this was an issue of port forwarding at my router. I've never run a full node that REQUIRED incoming connections in order to operate. This is feeling even more centralized...
So I set my router to forward all ports in the range 8000 to 9000 to my benchmark machine. Finally, the node ran successfully and it started downloading a snapshot at nearly 30 MB/s.
It took 7 minutes to download the 8GB snapshot, 2.5 minutes to unpack it, 1 to load it, 3 min to index all the accounts. Prior to indexing, solana was only using a few GB of RAM. RAM usage ballooned as indexing began; clearly the indexes are stored in-memory for max performance.
Once indexing completed, solana was using 30GB of my 32GB of RAM. Unfortunately it was not yet done. It began building a "status cache" as well, which was clearly another in-memory data structure. At this point it started using my swap partition (on the NVME drive) and my machine became quite sluggish. After 13 minutes it finished and started pruning a bunch of data, at which point the swap and RAM usage dropped.
Solana's bottleneck generally appears to be bandwidth during snapshot download and RAM availability after the initial snapshot load and indexing.
It took 36 minutes to finish processing the snapshot and start processing new blocks to catch up to the blockchain tip. My machine hung for 6 minutes while reading from disk at 150 MB/s after it started processing new blocks. Then it filled up the rest of the RAM and started swapping again. At this point, 42 minutes after starting the node, the entire machine froze up for 5 minutes. When it became responsive again, the machine was using 20GB of RAM and 25GB of swap. This cycle continued on and off with the machine intermittently freezing.
At this point I was mainly interested to see if my machine would EVER catch up with the tip of the blockchain, as I could see on public block explorers that a new block was being added every 600 milliseconds.
However, 54 minutes after starting the node, it silently crashed. No error in the logs, thus it's unclear what failed specifically. Most likely it just ran out of RAM / swap and had a hard failure while trying to use memory space that was unavailable.
Snapshot sync of Solana 1.6.11 on my benchmark machine was able to download and index the snapshot in 36 minutes. However, it was never able to catch up to chain tip - after another 18 minutes of processing new blocks, the node crashed due to memory exhaustion.
— Jameson Lopp (@lopp) June 9, 2021
Clearly, if you try to run a solana node with < 64 GB of RAM, you're gonna have a bad time.
And remember: this is just for syncing from a trusted snapshot. Syncing from genesis and validating the entire transaction history is untenable at this point.
Zcash
Just like Bitcoin / Litecoin / Dogecoin, I use this config:
assumevalid=0 dbcache=24000
It took my benchmark machine 4 hours 56 min to run a full validation sync of zcash 4.4.0 to block 1,276,800. Zcashd only read 1.7 GB from disk and wrote 37.8 GB while using a max of 8.7 GB of RAM for cache. Still only seems to be using a single CPU core.
— Jameson Lopp (@lopp) June 7, 2021
Zcash has even less data to validate than Litecoin and Dogecoin, yet we can see it's slower than both of them when it comes to the data syncing velocity. It may be further behind on merging performance changes from upstream. At least it is making better use of the UTXO cache than Dogecoin.
The bottleneck appears to be software; it's only pegging a single CPU core rather than making use of all cores. It would sync a lot faster if validation was parallelized, though perhaps that's not possible due to how the zero knowledge proofs are validated?
In Conclusion
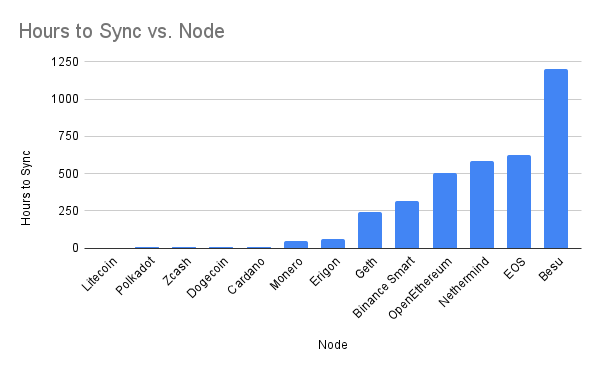
It took me nearly 2 months to run all of the sync tests listed above; it's getting to the point that you'd want to set up automated infrastructure to run them in parallel.
It's pretty clear that some of the newer "high performance" networks have almost none of their users running nodes and apparently few folks are even looking into the requirements for fully validating the system. This is concerning because an important aspect of any "decentralized" network's security model is if you can operate as a sovereign peer on the network who needs not ask permission to use the protocol.
Due to time constraints I doubt I'll continue performing this level of exhaustive testing on many different protocols, though I will endeavor to investigate new networks that come online to see how well their claims of decentralization hold up.